Science Fiction
Dictionary
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
 |
Watch What People Are Seeing Via Brain Scanning

Researchers at Purdue have developed a system that shows what people are seeing in real-world videos; the video is decoded from their fMRI brain scans.
(Human brain decoded)
Convolutional neural network (CNN) driven by image recognition has been shown to be able to explain cortical responses to static pictures at ventral-stream areas. Here, we further showed that such CNN could reliably predict and decode functional magnetic resonance imaging data from humans watching natural movies, despite its lack of any mechanism to account for temporal dynamics or feedback processing. Using separate data, encoding and decoding models were developed and evaluated for describing the bi-directional relationships between the CNN and the brain. Through the encoding models, the CNN-predicted areas covered not only the ventral stream, but also the dorsal stream, albeit to a lesser degree; single-voxel response was visualized as the specific pixel pattern that drove the response, revealing the distinct representation of individual cortical location; cortical activation was synthesized from natural images with high-throughput to map category representation, contrast, and selectivity. Through the decoding models, fMRI signals were directly decoded to estimate the feature representations in both visual and semantic spaces, for direct visual reconstruction and semantic categorization, respectively. These results corroborate, generalize, and extend previous findings, and highlight the value of using deep learning, as an all-in-one model of the visual cortex, to understand and decode natural vision.
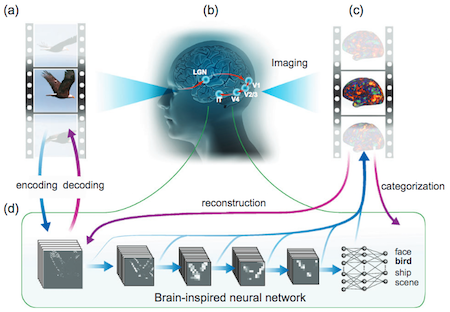
(Watching in near-real-time what the brain sees) Visual information generated by a video
(a) is processed in a cascade from the retina through the thalamus (LGN area) to several levels of the visual cortex
(b), detected from fMRI activity patterns
(c) and recorded. A powerful deep-learning technique
(d) then models this detected cortical visual processing. Called a convolutional neural network (CNN), this model transforms every video frame into multiple layers of features, ranging from orientations and colors (the first visual layer) to high-level object categories (face, bird, etc.) in semantic (meaning) space (the eighth layer). The trained CNN model can then be used to reverse this process, reconstructing the original videos even creating new videos that the CNN model had never watched.
(credit: Haiguang Wen et al./Cerebral Cortex)
In No, No, Not Rogov!, a 1958 story by Cordwainer Smith, an espionage machine is described that would actually let you see what another person saw by probing their brain:
He had then turned away from the reception of pure thought to the reception of visual and auditory images. Where the nerve-ends reached the brain itself, he had managed over the years to distinguish whole packets of microphenomena, and on some of these he had managed to get a fix.With infinitely delicate tuning he had succeeded one day in picking up in picking up the eyesight of their second chauffeur... and had managed to see through the other man's eyes as the other man, all unaware, washed their Zis limousine sixteen hundred meters away...
(Read more about Cordwainer Smith's espionage machine)
Via KurzweilAI.
Scroll down for more stories in the same category. (Story submitted 11/9/2017)
Follow this kind of news @Technovelgy.| Email | RSS | Blog It | Stumble | del.icio.us | Digg | Reddit |
Would
you like to contribute a story tip?
It's easy:
Get the URL of the story, and the related sf author, and add
it here.
Comment/Join discussion ( 0 )
Related News Stories - (" Medical ")
Health Kiosk Has No Human Doctor
'The electronic body analyzer had been developed...' - Michael Crichton, 1969.
NEO Brain Computer Interface (BCI)
'The remains of the lace took on the rough shape of a brain...' - Iain Banks, 2010.
MIT Computerized Bionic Leg Is Part Of The User
'The leg was to function, in a way, as a servo-mechanism operated by Larrys brain, through the mediation of the electronic brain in the leg.' - Charles Recour, 1949.
Bone-Building Drug Evenity Approved
'Compounds devised by the biochemists for the rapid building of bone...' - Edmond Hamilton, 1932.
Technovelgy (that's tech-novel-gee!) is devoted to the creative science inventions and ideas of sf authors. Look for the Invention Category that interests you, the Glossary, the Invention Timeline, or see what's New.
Science Fiction
Timeline
1600-1899
1900-1939
1940's 1950's
1960's 1970's
1980's 1990's
2000's 2010's
Current News
Collective Superintelligence Is At Hand!
'Maybe the individual intelligence of each Cubic pools into a group intelligence...'
Instant Journalists: Ordinary People With Cell Phones
'We'll show them whose planet this is!'
Health Kiosk Has No Human Doctor
'The electronic body analyzer had been developed...'
Meta's Horizon Studio's Unique Avatars From Text Prompts
'Looks like she has bought the Avatar Construction Set and put together her own...'
VaMEx Biomimetic Mars Robot Inspired By Skink
'Across the ground something small and metallic came, flashing in the dull sunlight of midday.'
NEO Brain Computer Interface (BCI)
'The remains of the lace took on the rough shape of a brain...'
Did Frank Herbert Predict Bistable Displays Like E-Ink?
'A broken circle with arrows pointing to a right-hand flow appeared in the chalf.'
Monolith One Giant Industrial Metal 3D-printer
'The object seemed melted together like wax nothing was distinguishable.'
'Mooncrete' Lunar Regolith Concrete (LRC)
'And here they began to build...'
China's 'Magpie Drone' Ornithopter
'Midges have many capabilities. To the untrained eye, they look like sparrows.'
MAI-Voice-2 Microsoft Text-To-Speech
'I made disks of my own voice to the number of five hundred very carefully chosen words.'
Tumblin' Tumbleweed Rovers To Eplore Mars
'His sensors out and working, and the whirring of the tape that sucked up sight and sound and shape and smell and form...'
Tentacled Robot Captures Space Debris
Preventing annoying space debris build-up.
Prufrock-MB2 Ready In Nashville
'It sounds to me as though you had invented a kind of metal earthworm.'
DIY Robotic Content Farming
'The chief wheeled to the master machine and pressed a button.'
Reflect Orbital Sunlight On Demand
'I don't have to tell you about the seven two-mile-diameter orbital mirrors that circulate around the satellite, making it habitable.'